SELECT
데이터 조회 때 사용. 예를 들어 SELECT 컬럼들 FROM 테이블 WHERE 조건문
테이블 명이나 컬럼 명에는 Alias를 붙일 수 있고, 붙인 후 쿼리들은 Alias로 써야 인식한다.
(1) 문자함수
CHR( ASCII 코드) #ASCII코드는 128개의 문자를 숫자로 표현하도록 정의한 코드, 예를 들어 CHR(65)는 A
LOWER(String)
UPPER(String)
LTRIM(String, [Letters]) and RTRIM(String, [Letter]) #왼쪽공백, 오른쪽공백 제거 Letter 옵션이 있다면 그 글자가 인식됐을 때 제거
SELECT LTRIM(' 난 사과가 좋아. ') FROM DUAL; #결과값: '난 사과가 좋아. '
SELECT RTRIM('나는 SQLDDP를 공부하기 싫다.', 'DP') FROM DUAL; #결과값: 나는 SQLD를 공부하기 싫다.
TRIM([LEADING/TRAILING/BOTH], [Letter], [FROM] String) #왼쪽, 오른쪽 공백 모두 제거, Letter옵션은 한 글자만
SELECT TRIM(TRAILING 'I' FROM 'HYEYUNI') FROM DUAL #output:HYEYUN
SUBSTR(String, starting_point, [length]) #시작 포인트는 1이다.
LENGTH(String) #길이 반환
REPLACE(String, chr_before, [chr_after]) #
(2) 숫자함수
ABS(num) #절대값
SIGN(num) #양수면 1, 음수면 -1, 0이면 0 return
ROUND(num, [digit]) #지정한 소수점 자릿수까지 반올림. 디폴트 0으로
TRUNC(num, [digit]) #지정한 소수점 자릿수까지 버림
SELECT ROUND(158.73, 1) FROM DUAL; #output: 158.7
SELECT ROUND(158.73, -1) FROM DUAL; #output: 160
SELECT TRUNC(54.29, 1) FROM DUAL; #output: 54.2
SELECT TRUNC(54.29, -1) FROM DUAL; #output: 50, 1의자리를 버림하라 생각하면 쉽다.
CEIL(num) #올림한 '정수'반환 ex. 72.86은 73, -33.4는 -33
FLOOR(num) #내림한 '정수'반환 ex. -22.3은 -23, 22.3은 22
MODE(num1, num2) #num1을 num2로 나눈 나머지 반환
(2) 숫자함수
SYSDATE #yyyy-mm-dd hh:mm:ss 반환
EXTRACT ([YEAR/MONTH/DAY/HOUR/MINUTE/SECOND] FROM 날짜데이터)
SELECT EXTRACT (YEAR FROM SYSDATE) AS YEAR, #2023
EXTRACT (MONTH FROM SYSDATE) AS MONTH, #5
EXTRACT (DAY FROM SYSDATE) AS DAY FROM DUAL; #28
ADD_MONTHS(날짜데이터, 특정 개월 수) #만약 31일에서 1달 뒤인데 31일이 없다면 해당 월의 마지막 일자인 30일 반환
(3) 변환 함수
암시적 형변환은 TO_NUMBER(BIRTHDAY) = 20020304와 같이 내부적으로 BIRTHDAY컬럼을 NUMBER형으로 변환하는 것을 예시로 들 수 있다.
이 경우, 성능 저하를 불러올 수도 있고 에러를 뱉을 수도 있기 때문에 되도록이면 명시적 형변환을 사용하는 것이 좋다.
TO_NUMBER(String)
TO_CHAR(num or date [format])
TO_DATE(String, format)
SELECT TO_CHAR(SYSDATE, 'YYYYMMDD HH24MISS') FROM DUAL #output: 20240529 020621
#HH는 시(12), HH24는 시(24), MI는 분, SS는 초
SELECT TO_DATE('20240529', 'YYYYMMDD') FROM DUAL #output: 2021-06-02
#포맷 형식의 문자형 데이터를 날짜형으로 변환
(3) NULL 관련 함수
NVL(factor1, factor2) # factor1이 NULL이면 factor2 반환. 아니면 factor1 반환
NULLIF(factor1, factor2) # factor1과 factor2가 같으면 NULL 반환. 아니면 factor1 반환.
COALESCE(factor1, factor2, factor3 ...) #NULL이 아닌 최초 factor 반환

CASE(SQL), DECODE(Oracle)
케이스는 함수보다는 구문에 가깝다고 볼 수 있음.
CASE WHEN SUBWAY_LINE = '1' THEN 'BLUE'
WHEN SUBWAY_LINE = '2' THEN 'GREEN'
WHEN SUBWAY_LINE = '3' THEN 'ORANGE'
[ELSE 'GRAY']
END
DECODE(SUBWAY_LINE, '1', 'BLUE', '2, 'GREEN', '3', ORANGE' ['GRAY']
WHERE
DML(Data Manipulation Language): 원하는 데이터만 골라 수행할 수 있도록 함. (INSERT 제외)
- UPDATE
- DELETE
SELECT * FROM ENTERTAINER
WHERE NAME = '김민지'; #민지만
SELECT * FROM ENTERTAINER
WHERE NAME <> '김민지'; #민지가 아닌 모두
UPDATE ENTERTAINER SET AGENCY_NAME = 'SM' WHERE NAME = '태연';
DELETE FROM ENTERTAINER WHERE JOB = '가수';
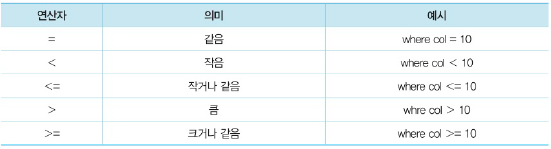
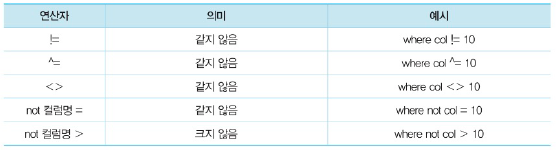
(1) (부정)비교연산자
(2) (부정)SQL 연산자
| SQL 연산자 | 부정SQL 연산자 |
| BETWEEN A AND B | NOT BETWEEN A AND B |
| LIKE : %는 여러 글자, _는 한 글자 | |
| IN(list) | NOT IN(list) |
| IS NULL | IS NOT NULL |
WHERE COL BETWEEN 1 AND 10
WHERE COL LIKE '브링미%'
WHERE COL LIKE '_링미커피'
WHERE COL IN (1, 3, 5) # 1, 3, 5 중 하나와 일치하는 값
WHERE COL IS NULL #결측치면
(3) 논리 연산자
AND, OR, NOT
GROUP BY, HAVING
HAVING은 GROUP BY 뒤에 나오는 조건문으로 그룹바이 뒤에 골라내는 역할을 한다고 생각하면 쉽다.
GROUP BY에서 자주 쓰이는 함수는 집계함수(COUNT, SUM, AVG, MIN, MAX)가 있다.
GROUP BY는 작업에 비용이 꽤나 들기 때문에, GROUP BY 전에 SELECT, WHERE 절에서 데이터 량을 최대한 거른 후에 진행하는 것이 맞다.
HAVING 절의 경우 논리적으로 SELECT 절 전에 수행되기 때문에 SELECT 절에 명시되지 않은 집계함수로도 조건 부여가 가능하다.
그렇다고 WHERE절에서 쓰일 수 있는 조건까지 HAVING에 넣으면 성능이 안좋아질 수 있다.
Example)
Q. 2021년 1학기의 수학 평균 점수가 90점 이상인 학생을 구하는 SQL로 가장 적절한 것은?
A. 집계함수인 AVG는 HAVING절을 이용해야 하고, HAVING 절은 SELECT 절보다 먼저 수행되기 때문에 다음과 같은 쿼리가 적당하다.
SELECT STUDENT_NO, AVG(MATH_SCORE) AS AVG FROM STUDENT_SCORE
WHERE YEAR = '2021' AND SEMESTER = '1'
GROUP BY STUDENT_NO
HAVING AVG(MATH_SCORE) > 90; #AVG로 표현하면 틀림. SELECT 이전에 수행되는 것이 HAVING문구
ORDER BY
Question. SELECT / FROM / WHERE / GROUP BY / HAVING / ORDER BY 절이 있다면 SELECT 문의 수행 순서는 과연 어떨까?
Answer. FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
ORDER BY는 ASC, DESC 함수를 사용하고, 일반적으로 기준이 되는 컬럼 뒤에 함수를 적는다.
또한 ORDER BY는 가장 마지막에 수행되기 때문에 SELECT에서 사용된 Alias를 받아와야 오류가 없다.
SELECT NAME, STUDENT_NO FROM STUDENT_INFO ORDER BY NAME DESC;
SELECT GRADE, NAME, MEMBER_NO FROM MEMBERINFO
ORDER BY GRADE, NAME; #GRADE 오름차순, 그 안에서 이름 오름차순
SELECT GRADE, NAME, MEMBER_NO FROM MEMBERINFO
ORDER BY GRADE DESC, NAME; #GRADE를 내림차순, 그 안에서 이름 오름차순