1. 데이터란
Data(자료): 데이터 객체(object)와 그들의 속성(attributes)의 집합체

1.1 속성/속성값/객체
속성(Attribute): 객체의 특성 (ex. 사람의 눈 색깔, 온도)
다른 말로는 variable, field characteristic, dimension, feature 가 있다.
속성값(Attribute values): 특정한 객체의 속성에 속한 숫자나 기호들
[특징1] 같은 속성이 다른 속성값으로 표현될 수 있다. ex) 키는 피트나 미터로 표현된다.
[특징2] 다른 속성들이 같은 값의 세트로 표현될 수 있다. ex) ID와 나이는 둘 다 정수(integer)로 표현된다.
속성 측정에서 속성의 특성을 전부 나타내지 못하는 경우가 있다. 가장 대표적인 예시로 Length(길이) 측정이 있다.
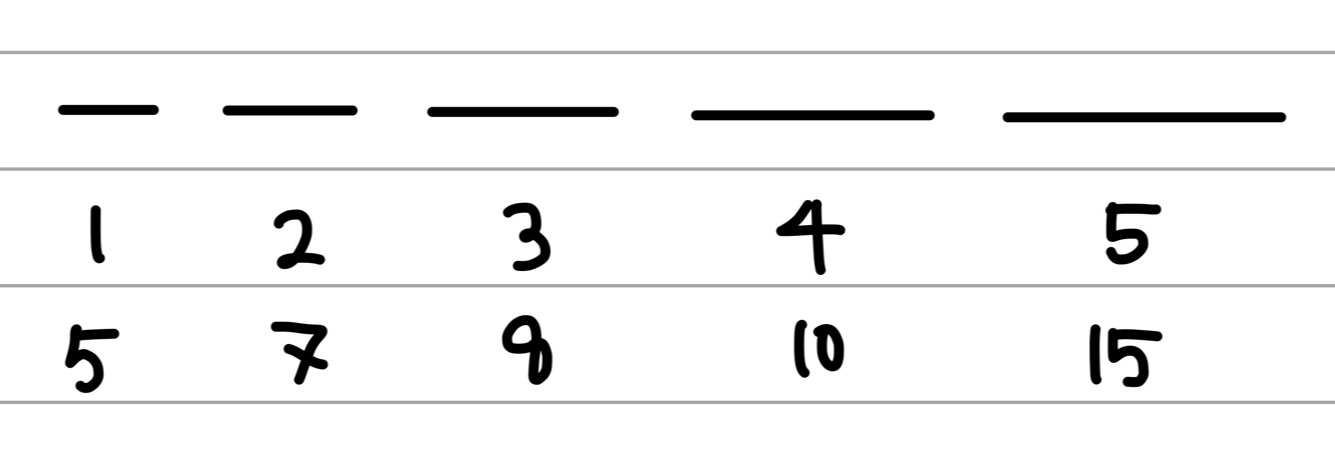
Fig 1.1 을 참고하자면, 길이를 표현하는 데에 있어서 1,2,3,4,5 의 경우는 순서와 덧셈특성(additivity properties)를 보여준다. 하지만 5,7,8,10,15의 경우는 길이의 순서만을 보여준다.
객체(Object): 속성들의 집합
다른 말로는 record, point, case, sample, entity, instance 가 있다.
1.2 속성의 종류(Types of Attributes)
| 대분류 | 소분류 | 가능연산 | 예시 | 사용범위 |
| Categorical (=Qualitative) |
Nominal | distinctness (=,/=) | 우편번호, 학번, 성별 | 최빈값, 엔트로피, contingency correlation, 카이스퀘어 테스트 |
| Ordinal | distinctness + order (=,/=,>,<) | 광물의 강도, 학년 | 중앙값, 분위수, rank correlation, 부호검정 | |
| Numeric (=Quantitative) |
Interval | distinctness + order(=,/=,>,<) + meaningful differences (+,-) |
날짜, C나F 단위 온도 | 평균, 표준편차, 피어슨 상관계수, t, F 테스트 |
| Ratio | distinctness + order (=,/=,>,<) + meaningful differences (+,-) + ratios are meaningful (/,*) |
절대온도, 길이, 질량, 나이 | 기하평균, 하모닉평균 |
Comment!
보통 Ratio랑 Interval의 차이를 묻는데, "0"이 절대적인 0의 의미가 있으면 Ratio, 아니면 Interval이 된다. 쉽게 생각해서 섭씨와 화씨의 0도는 서로 transformation을 하면 0이 아닌 것이다.
Discrete Attribute: 주로 정수로 표현되는, 셀 수 있는 값들
Continuous Attribute: 실수를 속성값으로 하고, 주로 Floating point variable로 표현된다.
Asymmetric Attribute: 두 개의 state가 동등하게 중요한 경우가 아닐 때, 예를 들어 코로나 테스트의 음성보다 양성반응이 더 중요한 경우이다.
근데, 속성을 나누는 것이 그렇게 중요한 것이 아닌게... 실제 데이터들은 노이즈가 많이 껴있고, 비슷비슷해서 속성을 타입별로 나누는 것이 썩 좋지는 않다고 한다.
2. 데이터 특성(Characteristics of Data)
1. Dimensionality(num of attributes)
차원성인데, 보통 한 객체를 이루는 속성들이 많아질 수록 차원이 높아진다. 그리고 그 객체들의 모임인 데이터 또한 고차원으로 된다는 것. 오히려 이 경우 차원의 저주가 일어날 수 있으며, 속성들이 데이터 갯수보다 많은 경우 차원축소 방법들을 고려해야 한다.
2. Sparsity
데이터는 마치 구멍이 송송 뚫린 치즈같을수록 좋은 데이터라고 볼 수 있다. 반은 비어있고 반은 차있는 데이터들이 서로 클러스터링을 했을 때 의미를 창출하기가 쉬운 것이다, 이거는 차원성과 비슷하다고 생각하면 되는데, 오히려 너무 많은 정보들로 가득 차 노이즈가 발생하고, 어디서든 의미가 있는 아웃풋을 낼 수 없을 땐 또 차원의 저주가 일어난다고 생각하면 된다.. 뭐지 이 차원의 굴레
3. Resolution
저해상도/ 고해상도에 따라 학습도 다르게 한다..같은데 이건 잘 모르겠다.
4. Size
데이터의 사이즈가 큰지, 작은지에 따라 다른 분석법을 적용할 수 있을 것이다.
3. 데이터 종류(Types of Datasets)
1. Record
Data Matrix: 우리가 생각하는 엑셀과 같은 형식들이 Record 형식들이다. 위의 그림1은 5X4 매트릭스라고 볼 수 있다.
Document data: Bag of Words 처럼 각각의 단어들을 카운트한 것들
Transaction Data: 데이터의 특별한 경우, 거래내역을 record data로 표현할 수 있다.
2. Graph
우리가 생각하는 그래프들이 다 그래프데이터다! 사진의 경우도 그래프로 생각할 수 있는데, RGB의 고유 숫자를 활용하여 (X,Y) 로케이션에 넣는다고 생각하면 그래프라고도 볼 수 있음.
3. Ordered
genomic sequence data, spatio-temporal data와 같은 데이터들을 말한다.
'딥러닝' 카테고리의 다른 글
| 1과목: 데이터 수집 및 저장 계획 (0) | 2023.04.07 |
|---|---|
| [데이터 시각화] 그래프 (0) | 2023.04.01 |
| Information(엔트로피, 상호정보량) (0) | 2023.04.01 |
| Similarity(유사도) (0) | 2023.04.01 |
| 데이터의 품질 (Data Quality) (0) | 2023.04.01 |