데이터 분석을 하기 위한 Preprocessing으로 가장 중요한건 내가 가진 Raw Data에서 노이즈, 이상치, 결측치, 중복데이터, 잘못된 데이터 등을 제거함으로 내 목적에 맞는 데이터로 정돈시키는 것이다. (실제 데이터는 항상 지저분하기 때문..)
품질에 영향을 주는 요인들에 대해 간단히 살펴보자 :>
1. Data Quality
1.1 Noise
객체로서 노이즈는 관련없는 객체를 뜻하고, 속성으로서의 노이즈는 원래 값에서의 다른 부분을 뜻한다. 예를 들어 통화음질이 안 좋아 왜곡된 사람의 목소리라던지, 노이즈가 낀 Sine wave같은 것들을 말한다.
1.2 Outliers
이상치는 다른 데이터 객체들 사이에 확 튄 객체를 뜻하는데, 이상치는 때에 따라 변경하던지 제거하던지를 결정한다. 가끔 이상치가 우리의 분석에서의 키가 되는 경우가 있는데, 예를 들어 금융 쪽에서 신용카드사기라던지, 불법 침입 감지와 같은 것들을 말한다.
1.3 Missing Values
결측치를 가진 객체나 변수를 아예 삭제하던지, 결측치 자체를 평균값과 같이 대체할 수 있는 수치로 대체하는 경우가 있다.
1.4 중복데이터
각기 다른 소스에서 데이터들을 병합하면서 중복된 데이터 객체들이 보이는 경우가 많다. 중복데이터는 꼭 삭제해서 데이터클리닝을 해야한다!!
2. Data Processing
<Key Term>
one-hot encoding or 1 of k encoding (보통 2진수로 해당되는 부분만 1로 한다고 원핫인코딩이라고 함)
범주형 자료들을 수치형 자료로 바꾸는 것이다. 컴퓨터는 멍청이라서 우리가 수치로 입력 안해주면 이해를 못한다.. 그래서 기본적으로 인코딩을 해주는 것이다. 밑에 그림들을 보면 바로 이해가 갈 것이다.
2.1 Feature Aggregation

변수들의 공통된 특성으로 묶어버리는 방법이다. 위 예시로는 한국기업과 국외기업의 특성으로 기업 4개를 2개로 범주화를 시킨 것이다.
2.2 Feature Selection
이는 예시가 필요없는 경우로, 말 그대로 내가 필요한 피쳐만 고르는 방법이다.
2.3 Feature Categorization
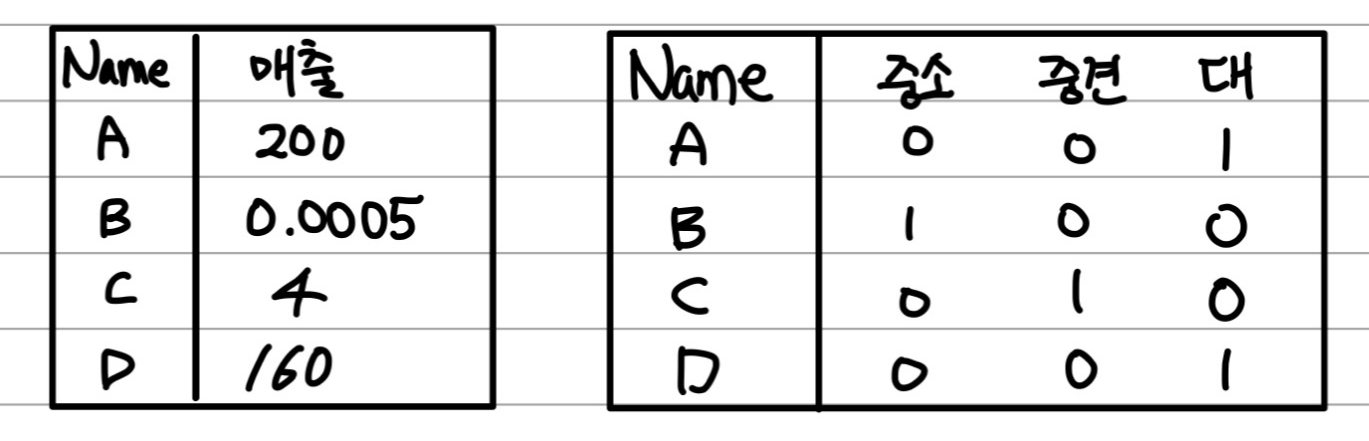
2.4 Feature Scaling
스케일링의 경우는 쓰일 때가 참 무궁무진하다. 로그 트랜스폼을 통하여 시계열의 경우 정상성을 확보하는 등.. 이거는 공부하면서 계속 등장할 것이다. 쉽게 말하자면 연구자가 목적을 위해 수치형 자료들을 정규화, 민맥스화 등등 스케일링하는 경우들 모두를 해당한다.
3. Discretization
연속형 변수를 이산형 변수로 변환해주는 과정으로, Binning이라고도 불린다.
(비지도적 학습, 지도적 학습 둘 다에서 쓰일 수 있다.) 카테고리컬하게 변환하면 분류형 모델에 쓰일 수 있다.
이산화를 하는 이유로는 Skewed된 변수들을 바꾸거나, 이상치의 영향을 최소한으로 줄이기 위해서 쓰이기도 한다.
기본적으로 Equal interval width 접근이나 Equal Frequency 접근을 많이 쓰는데, K-means 접근도 쓴다.
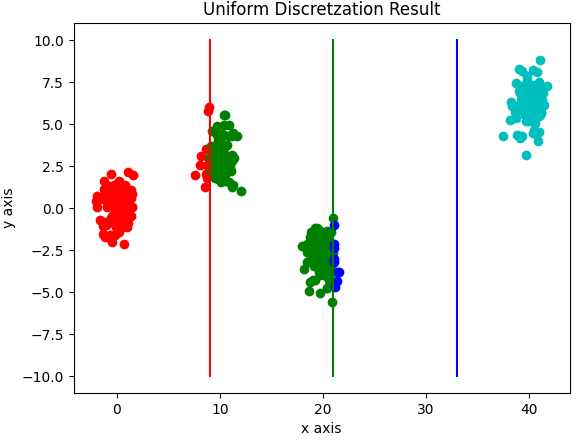
3.1 Uniform Discretization
Equal interval width를 이용하여 이산형으로 변환하는 과정이다.변환 과정은 아래와 같다.
$$ Width = \frac {Max(X) - Min(X)}{Bins} $$
예를 들어, 변수의 값들이 0과 100 사이고, 5개의 bin을 만들 것이라면 width = 20이 되고, bin들은 0-20, 20-40, ...가 된다.
3.2 KMeans Discretization
가장 정확도가 높고, 자주 쓰이는 이산화 접근 중 하나인데, KMeans의 센터들을 기준으로 분리할 때 쓴다. 스킷런에 Discretization 라이브러리가 있어서 간단하게 쓰일 수 있지만, 난 교수님이 쓰지말고 하라고 과제를 줘서... KMeans의 센트로이드를 구한다음에 그 값들로 interval 기준을 정했다.
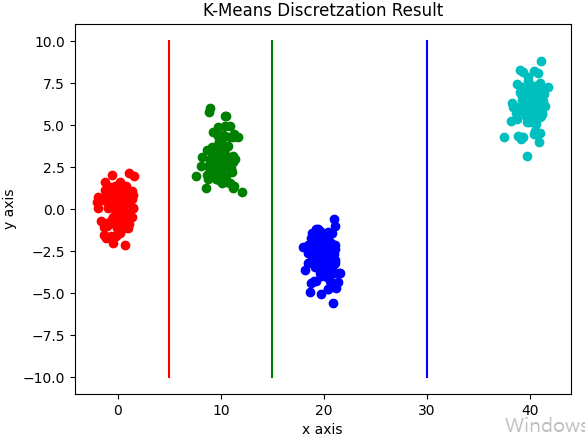
확실히 유니폼보다는 분류가 잘된 것을 볼 수 있다.
'딥러닝' 카테고리의 다른 글
| 1과목: 데이터 수집 및 저장 계획 (0) | 2023.04.07 |
|---|---|
| [데이터 시각화] 그래프 (0) | 2023.04.01 |
| Information(엔트로피, 상호정보량) (0) | 2023.04.01 |
| Similarity(유사도) (0) | 2023.04.01 |
| Data Types (0) | 2023.04.01 |